
声明
本节内容来源于 BiliBili视频数据结构与算法基础(青岛大学-王卓) 的 P101 - P107,本博客仅作笔记整理和学习记录,部分图片来自视频截图。
哈夫曼树的基本概念
- 路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。
- 结点的路径长度:两结点间路径上的分支数。
- 树的路径长度:从树根到每一个结点的路径长度之和。记作:TL
- 权(weight):将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
- 结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积。
- 树的带权路径长度:树中所有叶子结点的带权路径长度之和。记作:(其中w是权值,k是结点到根的路径长度)
哈夫曼树的性质
结点数目相同的二叉树中,完全二叉树是路径长度最短的二叉树。
-
哈夫曼树:最优树
带权路径长度(WPL)最短的树
“带权路径长度最短”是在“度相同”的树中比较而得的结果,因此有最优二叉树、最优三叉树之称等等。 -
哈夫曼树:最优二叉树
带权路径长度(WPL)最短的二叉树
因为构造这种树的算法是由哈夫曼教授于1952年提出的,所以被称为哈夫曼树,相应的算法称为哈夫曼算法。
满二叉树不一定是哈夫曼树
哈夫曼树中权越大的叶子离根越近
具有相同带权结点的哈夫曼树不惟一
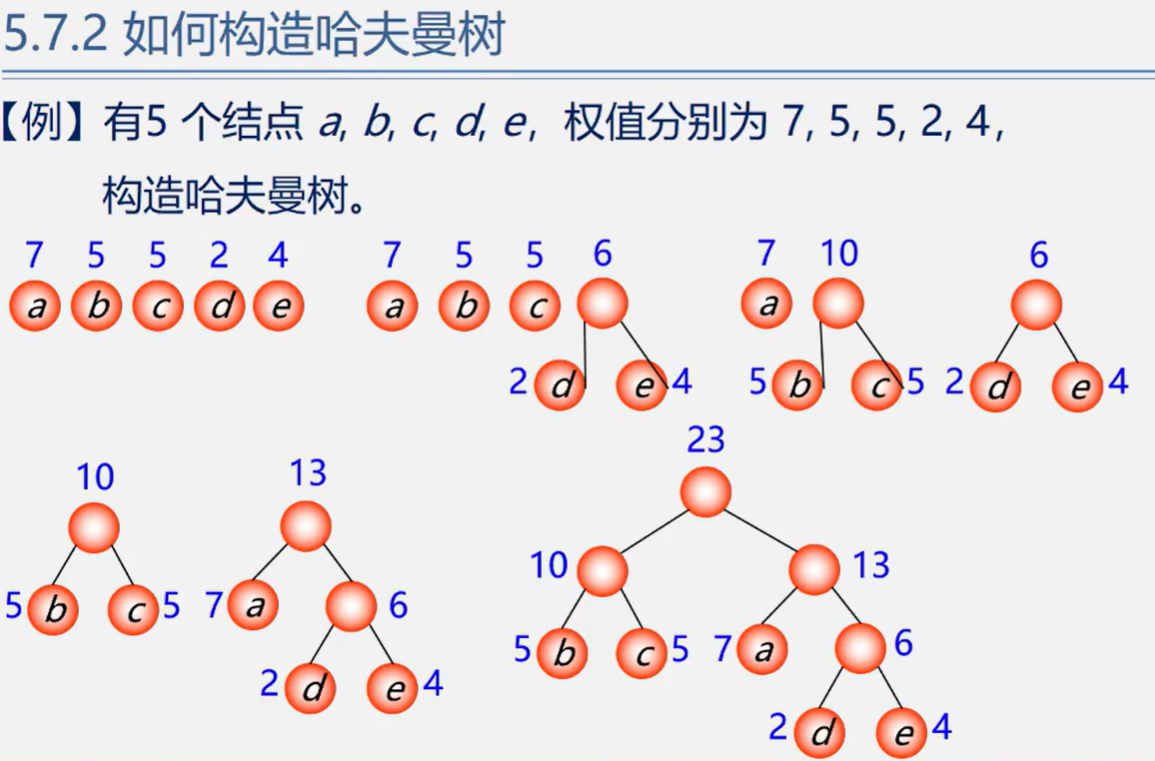
哈夫曼算法
即:构造哈夫曼树的方法
- 根据n个给定的权值 构成n棵二叉树的森林,其中T;只有一个带权为的根结点。
- 在F中选取两棵根结点的权值最少的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
- 在F中删除这两棵树,同时将新得到的二叉树加入森林中。
- 重复(2)和(3),直到森林中只有一棵树为止,这棵树即为哈夫曼树。
口诀:
构造森林全是根
选用两小造新树
删除两小添新人
重复二三剩单根
- 包含n个叶子结点的哈夫曼树中共有个结点。
- 哈夫曼树的结点的度数为或,没有度为的结点。
因为:包含n棵树的森林要经过次合并才能形成哈夫曼树,共产生个新结点。

总结:
- 在哈夫曼算法中,初始时有 棵二叉树,要经过 次合并最终形成哈夫曼树。
- 经过 次合并产生 个新结点,且这 个新结点都是具有两个孩子的分支结点。
可见:哈夫曼树中共有 个结点,且其所有的分支结点的度均不为1。
哈夫曼树的构造算法
- 初始化 : ;
- 输入初始 个叶子结点:设置 的weight值;
- 进行以下 次合并,依次产生 个结点 :
- 在中选两个未被选过(从 的结点中选)的weight最小的两个结点 和 ,s1、s2为两个最小结点下标;
- 修改 和 的parent值:
- ;
- ;
- 修改新产生的HT[i]:
- ;
- ;
- 采用顺序存储结构:一维数组
1 | HuffmanTree H; |
- 结点类型定义
1 | typedef struct { |
1 | // 构造哈夫曼树:哈夫曼算法 |
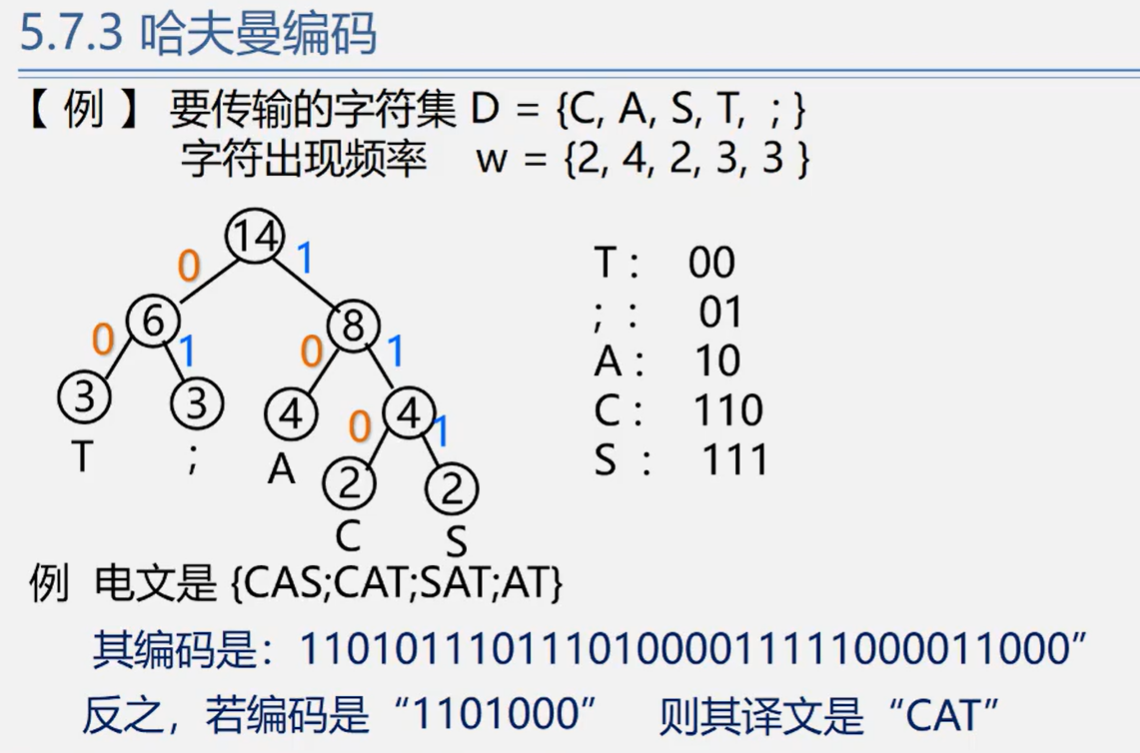
哈夫曼编码
在远程通讯中,要将待传字符转换成由二进制的字符串:
- 设要传送的字符串为:ABACCDA
- 若编码为:A-00 B-01 C-10 D-11
- 则实际传输的字符串为:00010010101100
若将编码设计为长度不等的二进制编码,即让待传字符串中出现次数较多的字符采用尽可能短的编码,则转换的二进制字符串便可能减少。
- 设要传送的字符串为:ABACCDA
- 若编码为:A-0 B-00 C-1 D-01
- 则实际传输的字符串为:000011010
- 出现了重码:0000 可以代表 AAAA、ABA、BB
关键:要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀。这种编码称做前缀编码。
问题:什么样的前缀码能使得电文总长最短?——哈夫曼编码
方法:
- 统计字符集中每个字符在电文中出现的平均概率(概率越大,要求编码越短)。
- 利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树。则概率越大的结点,路径越短。
- 在哈夫曼树的每个分支上标上0或1:
结点的左分支标0,右分支标1
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。
两个问题:
- 为什么哈夫曼编码能够保证是前缀编码?
因为没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码就不可能是其它叶结点编码的前缀 - 为什么哈夫曼编码能够保证字符编码总长最短?
因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
性质:
- 哈夫曼编码是前缀码
- 哈夫曼编码是最优前缀码
哈夫曼编码的算法实现
1 | void CreatHuffmanCode(HuffmanTree HT, HuffmanCode &HC, int n){ |
文件的编码和解码
编码:
- 输入各字符及其权值
- 构造哈夫曼树——
- 进行哈夫曼编码——
- 查 ,得到各字符的哈夫曼编码
解码:
- 构造哈夫曼树
- 依次读入二进制码
- 读入0,则走向左孩子;读入1,则走向右孩子④ 一旦到达某叶子时,即可译出字符
- 然后再从根出发继续译码,指导结束
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 沐阳先生的博客!
 微信
微信- 支付宝
- 爱发电



相关推荐

评论